人工智能技术日新月异,深度学习框架作为技术底座深刻影响着算法创新的速度与产业落地的深度。飞桨框架以五大核心突破回应时代命题,正式发布3.0版本。飞桨框架3.0实现了从底层硬件适配到顶层开发体验的全面进化,在训练效率、性能、兼容性等关键指标上建立新标杆,作为支撑千行百业智能化转型的"AI操作系统",此次升级不仅是技术参数的迭代,更是面向大模型工业化生产范式的革命性突破。无论是前沿算法研究还是产业级大模型落地,飞桨框架3.0都将成为开发者的首选利器。
作为中国首个自主研发的产业级深度学习平台,飞桨一直坚持开源路线,支撑产业智能化升级。2025年4月1日,飞桨框架迎来重大更新,发布飞桨框架3.0正式版。飞桨框架3.0版本不仅延续了飞桨框架2.0系列动静统一、训推一体的特性,更在自动并行、神经网络编译器、高阶自动微分等方面取得突破,为大模型时代的技术创新与产业应用提供了强大支撑,为开发者打造了一站式、高性能的深度学习开发体验。
飞桨框架3.0具备以下五大新特性:
1)动静统一自动并行:通过少量的张量切分标记,即可自动完成分布式切分信息的推导,Llama预训练场景减少80%的分布式相关代码开发。
2)大模型训推一体:依托高扩展性的中间表示(PIR)从模型压缩、推理计算、服务部署、多硬件推理全方位深度优化,支持文心4.5、文心X1等多款主流大模型,DeepSeek-R1满血版单机部署吞吐提升一倍。
3)科学计算高阶微分:通过高阶自动微分和神经网络编译器技术,微分方程求解速度比PyTorch快115%。
4)神经网络编译器:通过自动算子自动融合技术,无需手写CUDA等底层代码,部分算子执行速度提升4倍,模型端到端训练速度提升27.4%。
5)异构多芯适配:通过对硬件接入模块进行抽象,降低异构芯片与框架适配的复杂度,兼容硬件差异,初次跑通所需适配接口数比PyTorch减少56%,代码量减少80%。
背景概述
在大模型时代,深度学习框架的重要性愈发凸显,成为推动人工智能技术发展的核心引擎。算法、算力、数据作为人工智能技术的三大要素,其相互作用与协同发展不断催生着新的突破。越来越多的实例证明,算法创新能够发挥出更为显著的威力。DeepMind的AlphaFold3通过动态扩散算法突破蛋白质结构预测精度,已成功应用于抗疟疾等药物分子设计;DeepSeek通过算法创新,成功提升了DeepSeek V3模型的性价比,大幅降低了训练成本。这些突破性进展表明,算法创新正在重构技术发展的成本曲线。
然而,算法创新并非易事,当前算法工程师和科研人员在使用现有深度学习框架进行算法创新时,仍面临诸多挑战。
1)大模型分布式开发门槛高:大模型参数规模庞大,其分布式训练需使用复杂的并行策略,包括数据并行、张量并行、参数分片并行、流水线并行、序列并行、专家并行等。大模型开发中,如何实现多种并行策略的高效协同已成为关键瓶颈。
2)模型推理部署困难重重:由于算法训练和推理任务的计算、通信存在较大差别,算法工程师在完成模型算法创新后,往往难以直接应用于推理部署,需要大量的工程开发工作。
3)前沿模型架构灵活多变:科学智能(AI for Science)等新兴领域的快速发展,对深度学习框架提出了新的要求,包括求解复杂微分方程所需的高阶自动微分、傅里叶变换等科学计算操作、复数的高效运算等。
4)模型极致性能优化难度大:以大模型为代表的很多场景对训练推理速度有严苛要求,为突破计算瓶颈,工程实践中常需通过手写CUDA内核代码进行性能优化,这对算法工程师的底层编程能力提出了极高要求。
5)异构芯片适配成本高:AI应用场景丰富多样、算力需求巨大,单一芯片难以满足业务需求。而不同芯片之间的硬件架构、软件栈成熟度、开发接口差异大,业务适配成本高、软硬协同优化难。
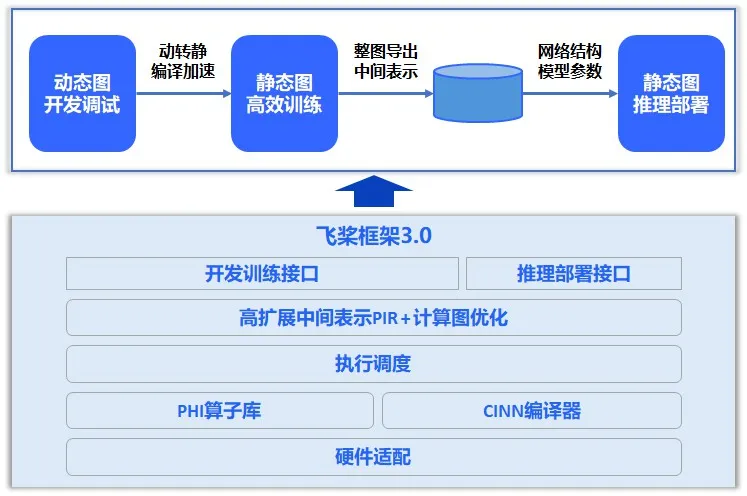
为此,飞桨新一代框架3.0应运而生:该版本提供了丰富的深度学习相关的各种开发接口;表示层专注于计算图的表达与转换,通过高可扩展中间表示PIR,实现动转静、自动微分、自动并行、算子组合以及计算图优化等核心功能;调度层负责对代码或计算图进行智能编排与高效调度,支持动态图和静态图两种不同的执行模式;算子层由神经网络编译器CINN和算子库PHI共同构成,涵盖了张量定义、算子定义、算子自动融合和算子内核实现等关键功能;适配层则用于实现与底层芯片适配,包括设备管理、算子适配、通信适配以及编译接入等功能。

飞桨框架3.0架构图
飞桨框架3.0凭借强大的功能和优化的设计,帮助算法工程师和科研人员以更低的成本进行算法创新,并实现产业应用。以百度文心大模型为例,飞桨框架3.0在训练、推理等方面为文心大模型提供端到端优化,训练方面重点提升训练吞吐、训练有效率和收敛效率,集群训练有效率超过98%;推理部署方面通过注意力机制量化推理、通用投机解码等技术提升推理吞吐和效率;全面支持文心4.5、文心X1等大模型的技术创新和产业应用。
全面支持自动并行训练
降低大模型开发训练门槛
在大模型时代,随着模型规模和训练数据量的不断增长,传统的单机单卡训练已无法满足需求,分布式并行训练成为加速大模型迭代的关键。然而,无论是动态图还是静态图,当前市场上的并行训练框架普遍存在使用成本高的问题。开发者既要熟知模型结构,还要深入了解并行策略和框架调度逻辑,使得大模型的开发和性能优化门槛非常高,制约了大模型的开发和训练效率。
针对这一痛点,飞桨提出了动静统一自动并行方案。该技术通过原生动态图的编程界面与自动并行能力,同时保障了灵活性和易用性,大幅降低了大模型并行训练的开发成本;同时,利用框架动静统一的优势,一键转静使用静态优化能力,提供极致的大模型并行训练性能。开发者仅需少量的张量切分标记,框架便能自动推导出所有张量和算子的分布式切分状态,并添加合适的通信算子,保证结果正确性。具体工作流程如下图所示:

动静统一自动并行流程图
飞桨框架3.0动静统一自动并行技术的具体特点如下:
1)简单易用,大幅降低大模型并行训练开发成本。飞桨自动并行功能允许用户在不考虑复杂分布式通信的情况下完成算法实现。仅需借助少量API调用,即可将算法转换为并行训练程序,显著简化开发过程。以Llama2的预训练为例,传统实现方式需要开发者精细调整通信策略,以确保正确高效执行,而自动并行实现方式相比传统方式减少80%的分布式核心代码,极大降低了开发复杂度。
2)全面可用,适用于众多大模型训练场景。基于飞桨大模型开发套件(PaddleNLP、PaddleMIX),飞桨框架已全面验证Llama、QwenVL等从大语言模型到多模态模型的预训练、精调阶段的自动并行训练。
3)轻松加速,一键动转静提供极致性能优化。得益于飞桨框架独特的动静统一设计,用户仅需简单添加一行代码,即可轻松实现从动态到静态的转换。这一转换使得我们能够充分利用多种静态优化技术,匹敌甚至超越经过极致优化的动态图训练效率。
4)协同文心,开源多项大模型独创优化策略。飞桨协同文心创新实现精细化重计算、稀疏注意力计算优化、灵活批次的流水线均衡优化等,这些优化技术在飞桨框架3.0中开源,助力开发者进行极致的大模型训练性能优化。
未来,我们将进一步探索无需使用张量切分标记的全自动并行,让开发者可以像写单机代码一样写分布式代码,进一步提升大模型的开发体验。
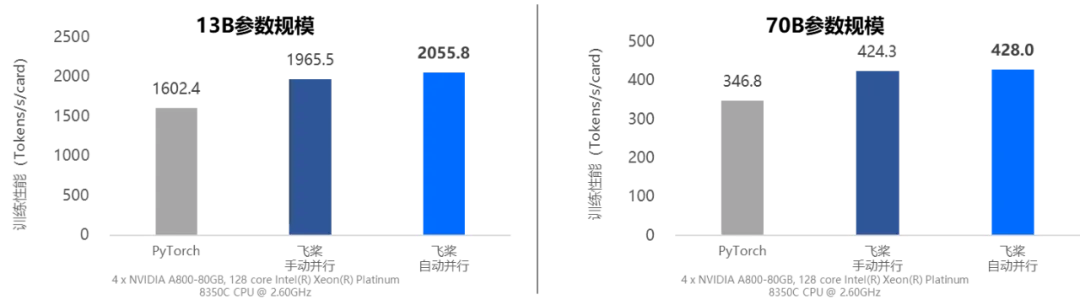
动静统一自动并行训练速度对比
大模型训推一体
提升推理部署效率
在完成模型的开发和训练后,我们需要面对推理部署场景的挑战:如何低门槛、低开发成本、快速地将模型部署到业务场景,并提供低时延、高吞吐、低算力成本的推理服务。自2.0版本起,飞桨便采用了“动静统一、训推一体”的设计理念,3.0版本也继续秉持这一理念,并在大模型场景下持续优化,发挥更大作用。
在推理部署方面,相较于动态图,静态图不仅可部署范围更为广泛,它能够通过整图导出的方式,摆脱对Python源代码和执行环境的依赖;而且更适合进行全局调优,可通过手写或者借助编译器自动实现算子融合等方式来加速推理过程。
得益于动静统一的架构和接口设计,飞桨能够完整支持动态图和静态图这两种不同的运行模式,并且具备出色的整图导出能力。飞桨的动转静整图导出成功率高达95%,高于PyTorch 62%。“训推一体”意味着能够在同一套框架下,尽可能复用训练和推理的代码,特别是复用模型组网代码。在完成模型的开发训练后,只需进行少量的开发工作,即可实现快速推理部署。与业界当前先使用PyTorch和DeepSpeed进行训练,再采用vLLM、SGLang、ONNXRuntime等推理引擎进行推理部署的方案相比,飞桨采用训练和推理使用同一套框架的方式,能够有效避免不同框架之间可能出现的版本兼容性问题,以及因模型结构变化、中间表示差异、算子实现差异等带来的困扰。
飞桨训推一体架构设计
大模型的推理部署需要更好地平衡成本、性能和效果,飞桨框架3.0全面升级了大模型推理能力,依托高扩展性的中间表示(PIR)从模型压缩、推理计算、服务部署、多硬件推理全方位深度优化,能够支持众多开源大模型进行高性能推理,并在DeepSeek V3/R1上取得了突出的性能表现。飞桨框架3.0支持了DeepSeek V3/R1满血版及其系列蒸馏版模型的FP8推理,并且提供INT8量化功能,破除了Hopper架构的限制。此外,还引入了4比特量化推理,使得用户可以单机部署,降低成本的同时显著提升系统吞吐一倍,提供了更为高效、经济的部署方案。在性能优化方面,我们对MLA算子进行多级流水线编排、精细的寄存器及共享内存分配优化,性能相比FlashMLA最高可提升23%。综合FP8矩阵计算调优及动态量化算子优化等基于飞桨框架3.0的DeepSeek R1 FP8推理,单机每秒输出token数超1000;若采用4比特单机部署方案,每秒输出token数可达2000以上,推理性能显著领先其他开源方案。此外,还支持了MTP投机解码,突破大批次推理加速,在解码速度保持不变的情况下,吞吐提升144%;吞吐接近的情况下,解码速度提升42%。针对长序列Prefill阶段,通过注意力计算动态量化,首token推理速度提升37%。
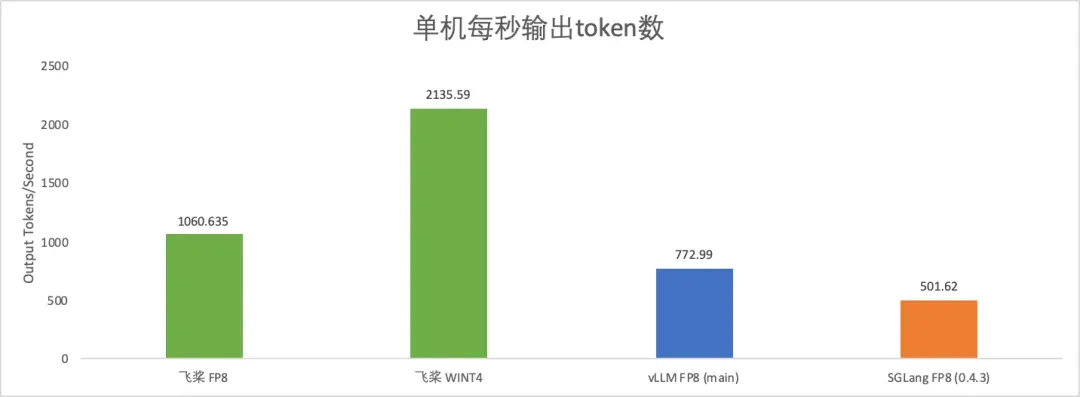
DeepSeek模型单机推理速度对比(H800上256并发不含MTP测试)
助力科学前沿探索
提升微分方程求解速度
人工智能正以前所未有的方式重塑科学研究范式,成为推动科学发现与技术创新的“超级加速器”。例如,布朗大学团队首次提出物理信息神经网络(PINNs),通过自动微分实现物理约束与数据驱动的结合;NVIDIA实验室提出全球高分辨率气象预报模型FourCastNet,预报时长从几个小时缩短到几秒钟;2025年1月,Baker团队在《Nature》发表研究,利用RFdiffusion算法从头设计出能够高效中和眼镜蛇蛇毒中三指毒素的蛋白质。科学智能(AI for Science)为解决科学问题带来新方法的同时,也对深度学习框架带来诸多新挑战。对科学问题机理化的探索,需要深度学习框架能够具备更加丰富的各类计算表达能力,如高阶自动微分、傅里叶变换、复数运算、高阶优化器等等;此外,如何实现深度学习框架与传统科学计算工具链的协同,也是需要思考的问题。
为了解决这些挑战,飞桨框架3.0提出了基于组合算子的高阶自动微分技术,如下图所示,该技术的核心思想是将复杂算子(如log_softmax)拆解为多个基础算子的组合,然后对这些基础算子进行一阶自动微分变换。重要的是,基础算子经过一阶自动微分变换后,其所得的计算图仍然由基础算子构成。通过反复应用一阶自动微分规则,我们可以轻松地获得高阶自动微分的结果。这一机制不仅完美兼容动态图模式和静态图模式,而且在动态图模式下支持N+1阶微分的灵活拆分,同时在静态图模式下能够进行高效的编译器融合优化。
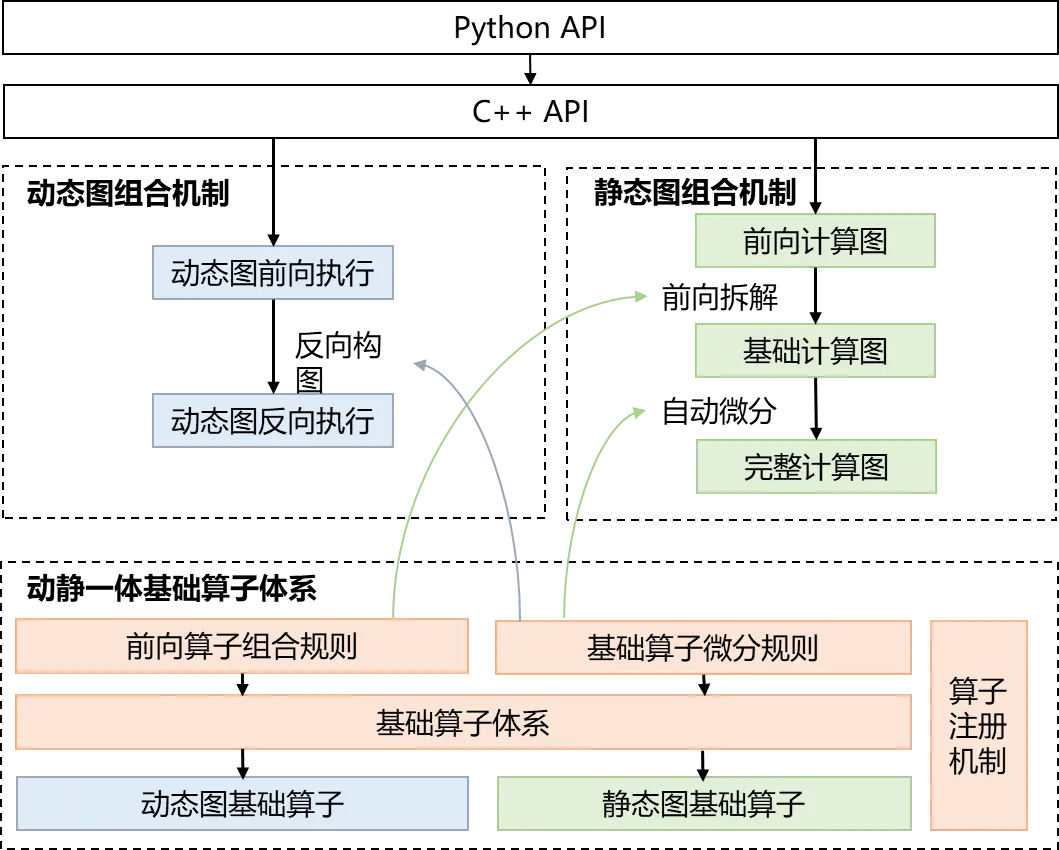
基于组合算子的高阶自动微分技术
基于飞桨框架的高阶自动微分和编译优化技术,实现了方程求解类模型性能的大幅提升,英伟达Modulus的41个不同方程实验显示,飞桨的微分方程求解速度比PyTorch开启编译器优化后的2.6版本平均快 115%。此外,飞桨还实现了傅里叶变换、复数运算、高阶优化器等功能,这些方法在航空航天、汽车船舶、气象海洋、生命科学等多个领域都具有广泛的应用潜力,为科学研究和工程实践提供了有力的支持。在模型层面,我们成功研发了赛桨(PaddleScience)、螺旋桨(PaddleHelix)等系列开发套件,为科学计算提供了更为便捷、高效的解决方案。飞桨对DeepXDE、Modulus等主流开源科学计算工具进行了广泛适配,并成为DeepXDE的默认推荐后端。
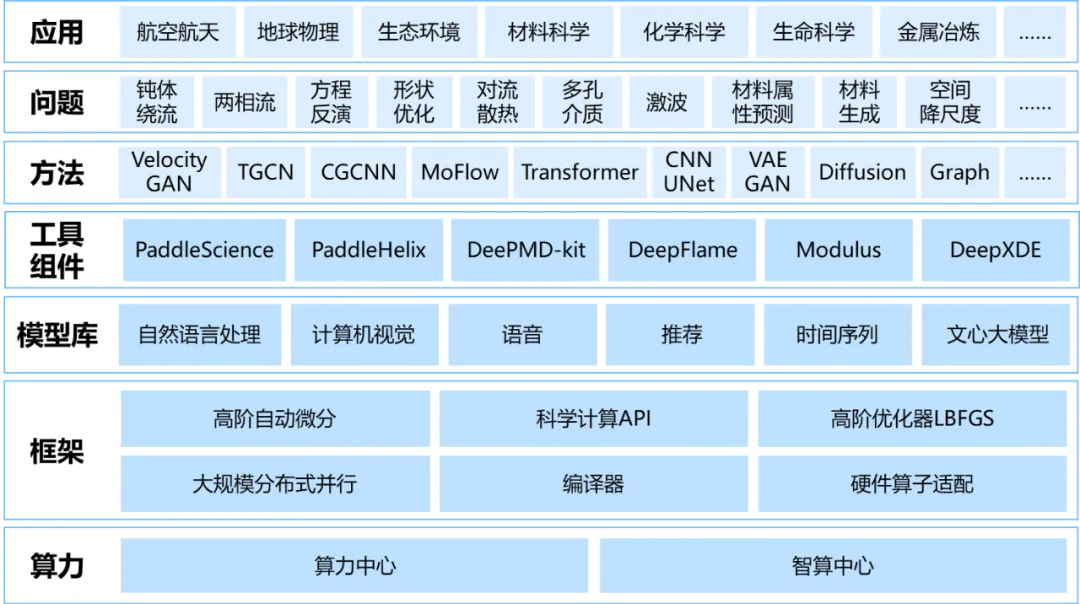
飞桨AI for Science全景图
神经网络编译器技术
实现框架通用性能提升
在众多深度学习的应用场景中,如大模型训练、自动驾驶等,对模型的训练与推理速度均提出了极高的要求。然而,要实现训练与推理速度的提升并非易事,这需要我们紧密结合模型结构与硬件特性,开展大量的工程实现与优化工作。在模型结构层面,模型结构正日益呈现出多样化的趋势,从基础的全连接网络,到复杂的卷积神经网络、循环神经网络、Attention网络、状态空间模型、图神经网络等,每一种模型结构都拥有其独特的计算模式与优化需求。在硬件特性方面,算力的增长速度远远超过了访存性能的提升,访存性能的瓶颈限制了访存密集型算子(如归一化层、激活函数等)的执行效率。特别是,当前市场上硬件平台种类繁多,我们需要投入大量的人力物力,进行针对性的优化工作,这将严重拖慢算法创新和产业应用的速度。
让我们通过一个实例来阐释这一点。我们以Llama模型中经常使用的RMS Normalization(Root Mean Square Layer Normalization)为例,其计算公式相对简单明了。
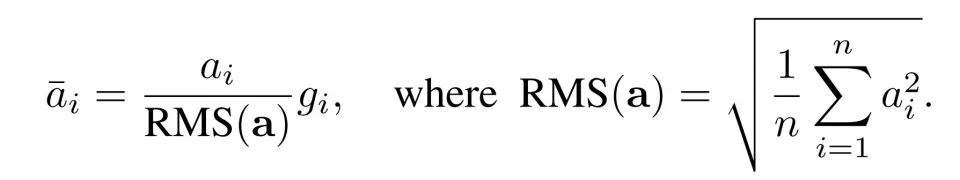
假设我们需要实现RMS Normalization的计算,最简单的办法是,我们可以使用飞桨框架提供的张量运算开发接口,调用平方、求和、除法、开根号等操作来完成,代码如下:

上述代码开发简单,但是由于存在大量的访存操作导致性能很差,且显存占比较多;为了突破访存瓶颈,开发者可以选择通过手写CUDA代码的方式实现一个融合的FusedRMSNorm算子,但是对于开发者要求更高,开发成本也更高,更重要的是这种方式极大降低了可维护性和灵活性。
为此,飞桨框架3.0研制了神经网络编译器CINN(Compiler Infrastructure for Neural Networks),相比于PyTorch 2.0的Inductor加Triton的两阶段编译方案,CINN支持直接从神经网络中间表述编译生成CUDA C代码,通过一阶段的编译方案,CINN避免了两阶段编译由于中间表示信息传递和表达能力限制所造成的信息损失,具备更通用的融合能力和更好的性能表现。具体一些技术创新如下:
1)以Reduce为核心的算子融合技术。摒弃传统的粗粒度pattern匹配模式,支持维度轴自动变换对齐融合,在保证计算正确性的同时,具有更强的算子融合能力,带来更大的性能优化潜力。
2)动静态维度的高效后端Kernel调优技术。算子全面支持reduce、broadcast、transpose等多种算子的不同组合方式,针对各类算子组合和数据类型,自适应不同维度大小与不同硬件配置,进行全场景高效调优。通过自动向量化提高BF16、FP16等小数据类型的访存效率。通过分析与分桶机制,实现动静态运行时配置生成,根据运行时的硬件配置,在无需profiling的情况下生成高效的kernel。
3)动态维度的复杂表达式化简技术。建立了分层化简体系,Lower、Schedule、CodeGen阶段执行不同等级化简方法,解决传统化简方法中多场景叠加后化简困难、化简不彻底问题。实现了复杂表达式结构化简,抽取融合算子经过编译、调优后的固定子结构进行专项化简,且灵活支持自定义化简方法。
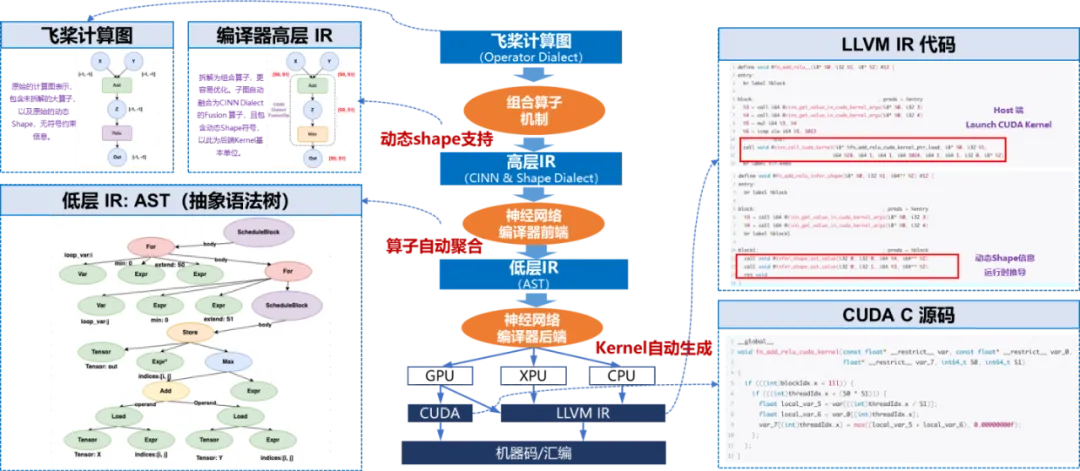
神经网络编译器CINN流程图
借助神经网络编译器技术,我们能够在维持高度灵活性和易用性的基础上,实现性能的显著提升。以下为A100平台上RMSNorm算子的性能测试结果:相较于采用Python开发接口组合实现的方式,经过编译优化后的算子运行速度提升了 4倍;即便与手动算子融合的方式相比,也实现了14%的性能提升,在灵活性与高性能之间寻找到了较为理想平衡点。我们在PaddleX开发套件里选取了超过 60模型进行实验,使用CINN编译器后超60%模型有显著性能提升,平均提升达 27.4%。重点模型相比PyTorch开启编译优化后的版本平均快18.4%。
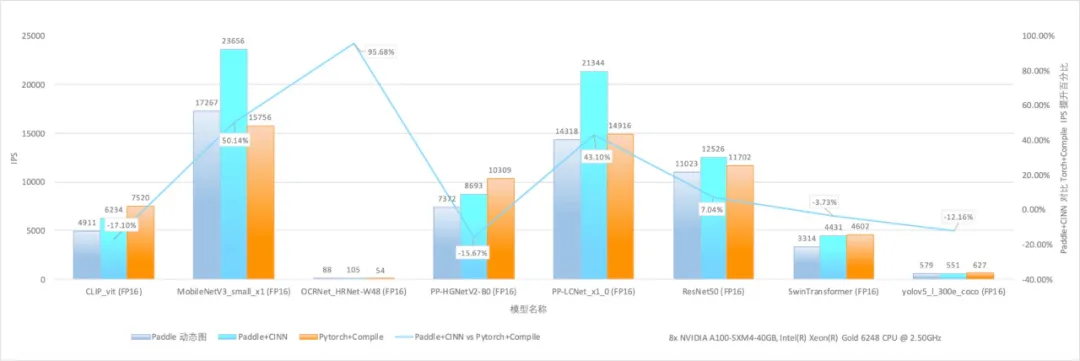
神经网络编译器CINN训练速度对比
在深度学习的创新探索与产业落地进程中,单一芯片往往难以满足复杂多变的业务需求,因此通常需要融合运用多种芯片来构建解决方案。大模型应用对于算力的需求极为庞大,而单一芯片的供应数量有限,远不足以支撑大模型的高效运行。不仅如此,不同场景对芯片性能有着差异化的严苛要求,单一芯片更是难以全面满足。例如,在大模型训练场景中,需要芯片具备大显存、高带宽以及高可靠性的特性;自动驾驶场景则强调低时延与高可靠性,以保障行车安全;端侧场景则聚焦于低功耗,以延长设备的续航时间。
飞桨框架自发布之初就考虑了多硬件适配的需求,历经持续迭代与演进,3.0版本构建了一套成熟且完善的多硬件统一适配方案:
1)飞桨聚焦于硬件接口的抽象。飞桨将硬件接口细分为设备管理、计算执行、分布式通信等多个类别,通过标准化的硬件接口成功屏蔽了不同芯片软件栈开发接口之间的差异。通过合理的抽象,减少了适配所需的接口数量,以昇腾芯片适配为例,初步跑通所需适配接口数比PyTorch方案减少56%,适配代码量减少80%。
2)基于标准化适配接口的定义,飞桨实现了松耦合、可插拔的架构。在此架构下,每类芯片仅需提供标准化适配接口的具体实现,便能轻松融入飞桨后端,极大地简化了芯片接入的流程。
3)考虑到不同芯片软件栈成熟度的差异,飞桨提供了丰富多样的接入方式,涵盖算子开发、算子映射、图接入、编译器接入等。针对大模型训练与推理需求,飞桨还具备全栈优化能力,如支持动静统一编程范式、超大规模分布式训练技术,提高了模型开发与部署效率。
4)飞桨与芯片厂商携手合作,共同构建了官方代码合入机制、例行发版机制和持续集成测试等研发基础设施,还建立了日级别例行功能与精度监测,保障开发者使用体验。
这些举措提升了研发效率,确保飞桨与各类芯片的适配工作高效、稳定推进。
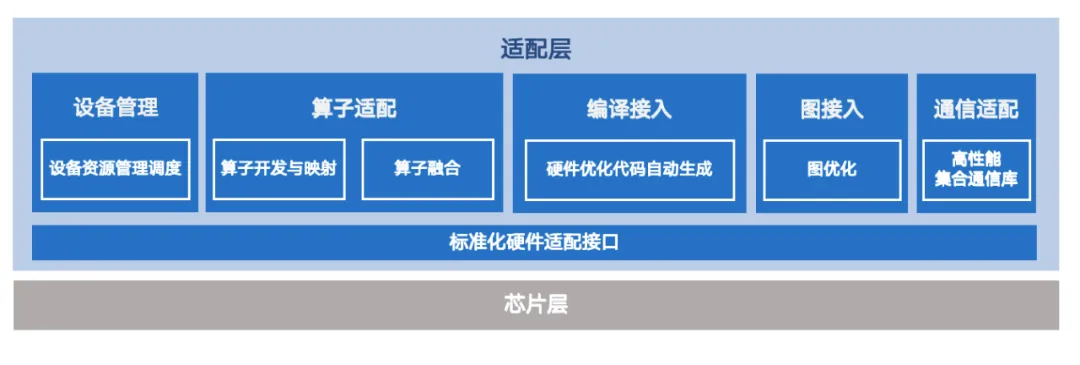
多硬件统一适配方案
基于前述技术,飞桨与芯片厂商紧密合作,携手共建蓬勃发展的硬件生态,当前飞桨已与超过40家成员单位开展合作,适配超过60个芯片系列。飞桨已与24家硬件厂商伙伴达成深度合作,共同推出了飞桨生态发行版。飞桨能够有效屏蔽底层硬件之间复杂多样的差异,为开发者提供简洁易用的开发接口。开发者只需编写一份代码,就可以让程序在不同芯片上顺畅运行,轻松实现业务的跨芯片迁移。飞桨的跨平台能力为业务在芯片选择方面带来了前所未有的灵活性,使开发者能够根据实际需求,更加自由、高效地规划业务部署。
总结
飞桨框架3.0面向大模型、异构多芯进行专属设计,向下适配异构多芯,充分释放硬件潜能;向上一体化支撑大模型的开发、训练、压缩、推理、部署全流程,并助力科学前沿探索。具备动静统一自动并行、大模型训推一体、科学计算高阶微分、神经网络编译器、异构多芯适配五大新特性。
1)动静统一自动并行:用户只需在单卡程序上进行少量的张量切分标记,飞桨就能将其自动转换为并行训练程序,大幅度降低了产业开发和训练的成本,使开发者能够更专注于模型和算法的创新。
2)大模型训推一体:同一套框架支持训练和推理,实现训练、推理代码复用和无缝衔接,为大模型的全流程提供了统一的开发体验和极致的训练效率,为产业提供了极致的开发体验。
3)科学计算高阶微分:科学计算提供了高阶自动微分、复数运算、傅里叶变换、编译优化、分布式训练等能力支撑,支持数学、力学、材料、气象、生物等领域科学探索,微分方程求解速度比PyTorch开启编译器优化后的2.6版本平均快115%。
4)神经网络编译器:采用与框架一体化的设计,能够支持生成式模型、科学计算模型等多种模型的高效训练与可变形状推理,在计算灵活性与高性能之间提供了良好的平衡点,显著降低了性能优化的成本。
5)异构多芯适配:构建了一套成熟且完善的多硬件统一适配方案,通过标准化接口屏蔽了不同芯片软件栈开发接口差异,实现可插拔架构,提供多种接入方式和基础设施,支撑硬件厂商合入4001个PR,包括26584个commits。
飞桨框架3.0将为开发者提供一个“动静统一、训推一体、自动并行、自动优化、广泛硬件适配”的深度学习框架,开发者可以像写单机代码一样写分布式代码,无需感知复杂的通信和调度逻辑,即可实现大模型的开发;可以像写数学公式一样用Python语言写神经网络,无需使用硬件开发语言编写复杂的算子内核代码,即可实现高效运行。目前3.0正式版本已面向开发者开放,并且兼容2.0版本的开发接口,非常欢迎广大开发者使用和反馈。




