
近日,IEEE 国际计算机视觉与模式识别会议CVPR 2021年度论文录用结果公布。作为全球计算机视觉三大顶会之一的CVPR,此次共收录7015篇有效投稿,最终有1663篇突出重围,接受率为23.7%;据悉,近两年CVPR录用结果均在25%左右,2020年更是降至22.1%,录用愈发严格。百度今年继续保持高质量输出,贡献了多篇计算机视觉相关的优质论文,涵盖图像语义分割、文本视频检索、3D目标检测、风格迁移、视频理解、迁移学习等多个研究方向,这些技术创新和突破将有助于智慧医疗、自动驾驶、智慧城市、智慧文娱、智能办公、智慧制造等场景的落地应用,进一步扩大中国AI技术的影响力,推进全球人工智能的发展。
此外,百度今年也联合澳大利亚悉尼科技大学和美国北卡罗来纳大学举办CVPR 2021 NAS Workshop(https://www.cvpr21-nas.com/),并已启动了相应的国际竞赛(https://www.cvpr21-nas.com/competition),探索神经网络结构中的搜索效率和效果问题。当前,来自全球的参赛队伍已超过400支。
以下为百度CVPR2021部分精选论文的亮点集锦。
1.一种快速元学习更新策略及其在有噪声标注数据上的应用
Faster Meta Update Strategy for Noise-Robust Deep Learning
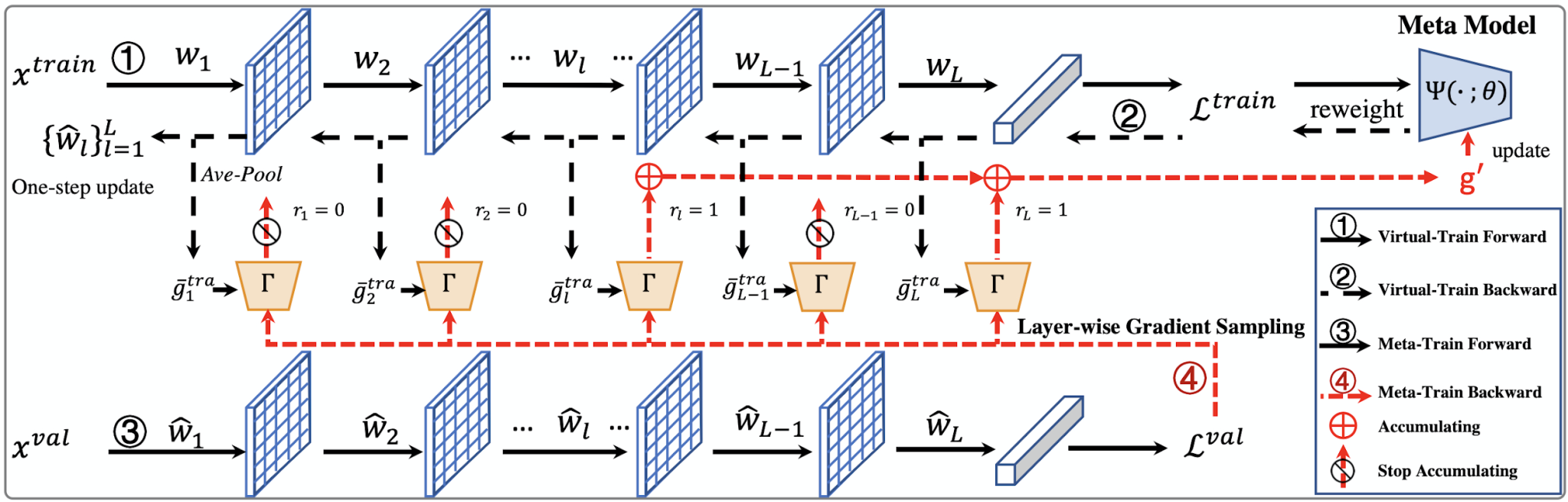
本论文已被CVPR2021接收为oral论文。基于meta-learning的方法在有噪声标注的图像分类中取得了显著的效果。这类方法往往需要大量的计算资源,而计算瓶颈在于meta-gradient的计算上。本文提出了一种高效的meta-learning更新方式:Faster Meta Update Strategy (FaMUS),加快了meta-learning的训练速度 (减少约2/3的训练时间),并提升了模型的性能。首先,本文发现meta-gradient的计算可以转换成一个逐层计算并累计的形式; 并且,meta-learning的更新只需少量层数在meta-gradient就可以完成。基于此,本文设计了一个layer-wise gradient sampler 加在网络的每一层上。根据sampler的输出,模型可以在训练过程中自适应地判断是否计算并收集该层网络的梯度。越少层的meta-gradient需要计算,网络更新时所需的计算资源越少,从而提升模型的计算效率。并且,本文发现FaMUS使得meta-learning更加稳定,从而提升了模型的性能。本文在有噪声的分类问题以及长尾分类问题都验证了本文方法的有效性。最后,在实际应用中,本文的方法可以扩展到大多数带有噪声标注数据的场景或者任务中,减少了模型对于高质量标注数据的依赖,具有较为广阔的应用空间。
2.面向无监督域适应图像语义分割的具有域感知能力的元损失校正方法
MetaCorrection: Domain-aware Meta Loss Correction for Unsupervised Domain Adaptation in Semantic Segmentation
论文链接: https://arxiv.org/abs/2103.05254
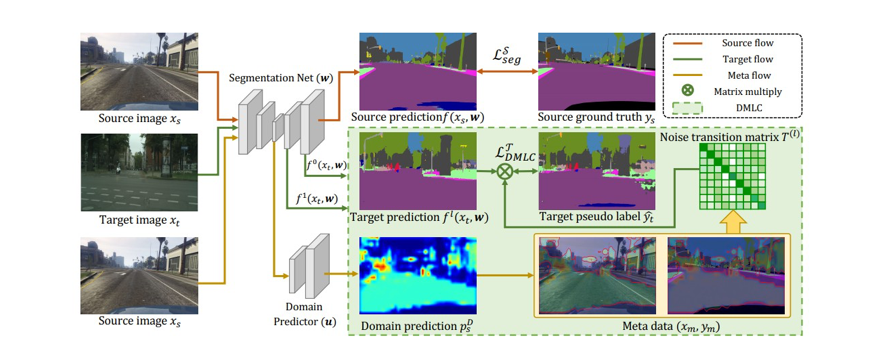
无监督域适应在跨域图像语义分割问题上取得了不错的效果。已有的基于自训练(self-training)方式的无监督域适应方法,通过对目标域分配伪标签来达到较好的域适应效果,但是这些伪标签不可避免的包含一些标签噪声。为了解决这一问题,本研究提出了“元校正”的新框架,该新框架利用域可知的元学习(Meta Learning)方式来促进误差校正。首先把包含噪声标签的伪标签通过一个噪声转移矩阵进行表达,然后通过在构建的元数据上,对此噪声转移矩阵进行优化,从而提高在目标域的性能。该新方案在GTA5→CityScapes、SYNHIA→CityScapes 两个标准自动驾驶场景数据库及Deathlon→NCI-ISBI13医学图像数据库跨域分割测试上都取得了非常不错的结果。该方案以后有望在自动驾驶图像及医学图像分割上取得落地。
3.基于跨任务场景结构知识迁移的单张深度图像超分辨率方法
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
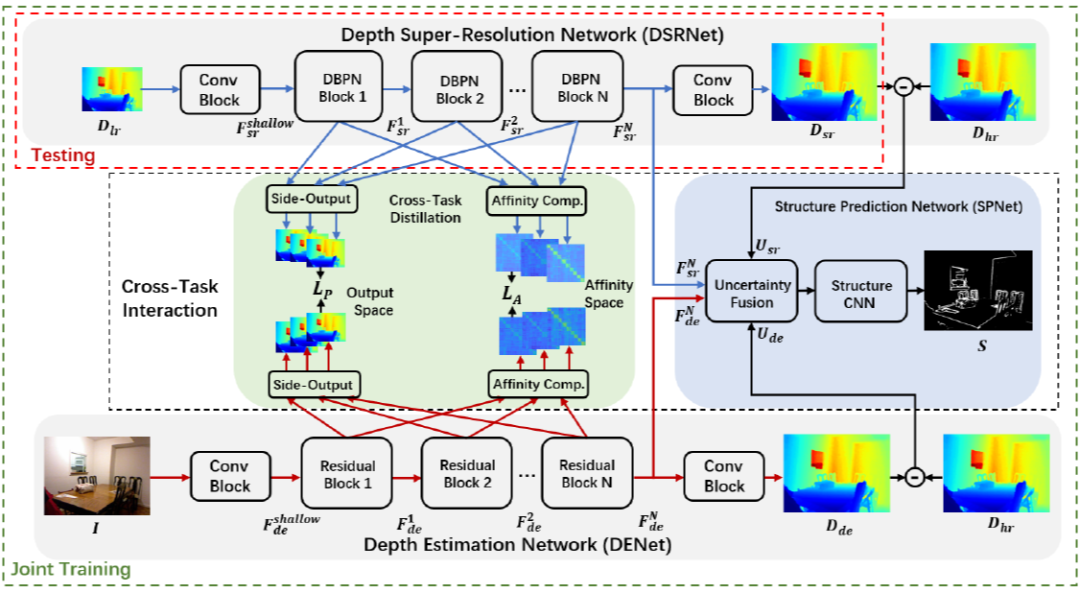
本项研究针对深度传感系统获取的场景深度图像分辨率低和细节丢失等问题,突破现有基于彩色指导的场景深度复原方法的局限性,首次提出基于跨任务场景结构知识迁移的单一场景深度图像超分辨率方法,在训练阶段从彩色图像蒸馏出场景结构信息来辅助提升深度复原性能,而测试阶段仅提供单张降质深度图像作为输入即可实现深度图像重建。该算法框架同时构造了深度估计任务(彩色图像为输入估计深度信息)及深度复原任务(低质量深度为输入估计高质量深度),并提出了基于师生角色交换的跨任务知识蒸馏策略以及不确定度引导的结构正则化学习来实现双边知识迁移,通过协同训练两个任务来提升深度超分辨率任务的性能。
在实际部署和测试中,所提出的方法具有模型轻量化、算法速度快等特点,且在缺少高分辨率彩色信息辅助的情况下仍可获得优异的性能。此项研究能有效应用于机器人室内导航及自动驾驶等领域。
4. 基于拉普拉斯金字塔网络的快速高质量艺术风格迁移
Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer

艺术风格迁移是指将一张风格图中的颜色和纹理风格迁移到一张内容图上,同时保存内容图的结构。相关算法在艺术图像生成、滤镜等领域有广泛的应用。目前基于前馈网络的风格化算法存在纹理迁移不干净、大尺度复杂纹理无法迁移等缺点;而目前基于优化的风格化方法虽然质量较高,但速度很慢。因此本文提出了一种能够生成高质量风格化图的快速前馈风格化网络——拉普拉斯金字塔风格化网络(LapStyle)。本文在实验中观察到,在低分辨率图像上更容易对结构复杂的大尺度纹理进行迁移,而在高分辨率图像上则更容易对局部小尺度纹理进行迁移。因此本文提出的LapStyle首先在低分辨率下迁移复杂纹理,再在高分辨率下对纹理的细节进行修正。在实验中,LapStyle迁移复杂纹理的效果显著超过了现有方法,同时能够在512分辨率下达到100fps的速度。本文的方法能够给用户带来新颖的体验,同时也能够实现移动端上的实时风格化效果。
5.一种通用的基于渲染的三维目标检测数据增强框架
LiDAR-Aug: A General Rendering-based Augmentation Framework for 3D Object Detection
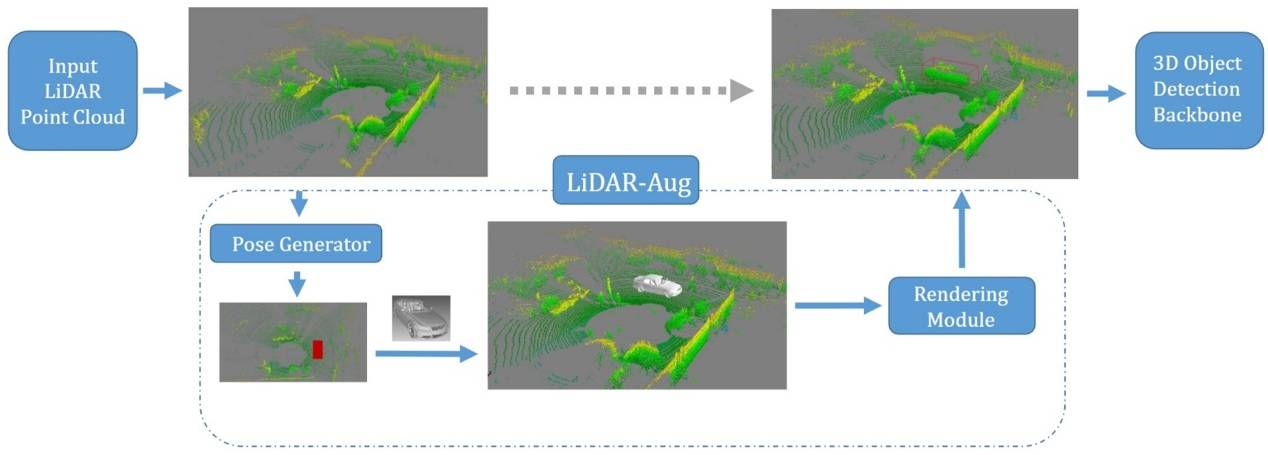
在自动驾驶中,感知模块非常重要,直接影响着后续的物体跟踪、轨迹预测、路径规划等模块。现在主流的三维目标检测算法都是基于深度学习。而对于基于深度学习的三维目标检测任务而言,带有标注信息的激光雷达点云数据非常关键。但是数据标注,尤其是基于点云的三维标注,本身成本高昂且耗时久,而数据增强则可以作为一个在模型训练阶段的一个重要的模块,来减缓对于数据标注的需求。在三维目标检测领域中,简单的将物体进行复制粘贴是一种非常常见的数据增强策略,但是往往忽略了物体之间的遮挡关系。为了解决这个问题,本文提出了一种基于计算机图形学渲染的激光雷达点云数据增强框架,LiDAR-Aug,来丰富训练数据从而提升目标检测的性能。
本文提出的数据增强模块使用即插即用的方式,可以很容易的集成到常见的目标检测框架中。同时,本文的增强算法对于检测算法适用性很广,可用于基于网格划分、基于柱状深度图表示等等检测算法中。比起常见的其他三维目标检测数据增强方法,本文的方法生成的增强数据,具有更广的多样性和真实感。最后,实验结果表明,本文提出的方法可以应用在主流的三维目标检测框架上,给自动驾驶的感知系统带来检测性能的提升,尤其是对于稀缺场景和类别,能带来较大的提升。
6.基于细粒度自适应对齐的文本视频检索
T2VLAD: Global-Local Sequence Alignment for Text-Video Retrieval
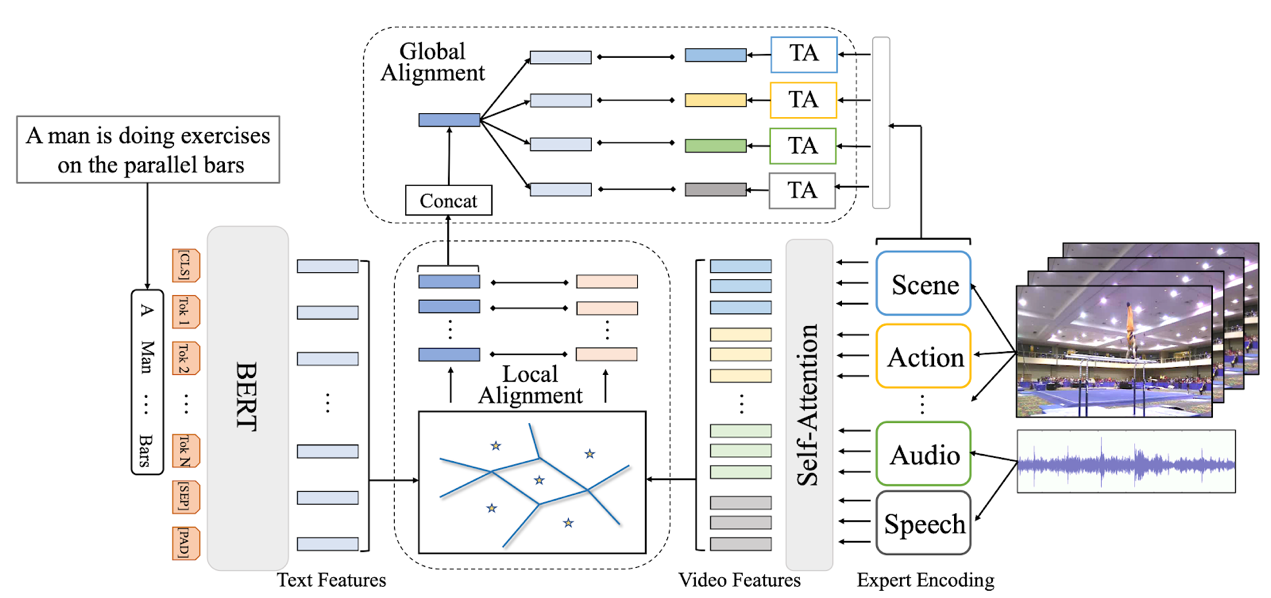
随着互联网视频尤其是短视频的火热,文本视频检索在近段时间获得了学术界和工业界的广泛关注。在引入多模态视频信息后,如何精细化地配准局部视频特征和自然语言特征成为这一问题的难点。本文提出自动化学习文本和视频信息共享的语义中心,并对自适应聚类后的局部特征做对应匹配,避免了复杂的计算,同时赋予了模型精细化理解语言和视频局部信息的能力。此外,本文的模型可以直接将多模态的视频信息(声音、动作、场景、speech、OCR、人脸等)映射到同一空间,利用同一组语义中心来做聚类融合,在一定程度上解决了多模态信息难以综合利用的问题。本文的模型在三个标准的Text-Video Retrieval Dataset上均取得了SOTA。对比Google在ECCV 2020上的发表的最新工作,本文的模型能在将运算时间降低一半的情况下,仅利用小规模标准数据集,在两个benchmark上超过其在亿级视频文本数据(Howto100M)上pretrain模型的检索结果。
7.VSPW:大规模自然视频场景分割数据集
VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild

近年来,图像语义分割方法已经有了长足的发展,而对视频语义分割的探索比较有限,一个原因是缺少足够规模的视频语义分割数据集。本文提出了一个大规模视频语义分割数据集,VSPW。VSPW数据集有着以下特点:(1)大规模、多场景标注:本数据集共标注3536个视频、251632帧像素级语义分割图片,涵盖了124个语义类别,标注数量远超之前的语义分割数据集(Cityscapes, CamVid)。与之前数据集仅关注街道场景不同,本数据集覆盖超过200种视频场景,极大丰富了数据集的多样性;(2)密集标注:之前数据集对视频数据标注很稀疏,比如Cityscapes,在30帧的视频片段中仅标注其中一帧。VSPW 数据集按照15f/s的帧率对视频片段标注,提供了更密集的标注数据;(3)高清视频标注:本数据集中,超过96%的视频数据分辨率在720P至4K之间。与图像语义分割相比,视频语义分割带来了新的挑战,比如,如何处理动态模糊的帧、如何高效地利用时序信息预测像素语义、如何保证预测结果时序上的稳定等等。
本文提供了一个基础的视频语义分割算法,利用时序的上下文信息来提升分割精度和稳定性。同时,本文还提出了针对视频分割时序稳定性的新的度量标准。期待VSPW 能促进针对视频语义分割领域的新算法不断涌现,解决上文提出的视频语义分割带来的新挑战。
8.基于视觉算法一次性去除雨滴和雨线
Removing Raindrops and Rain Streaks in One Go
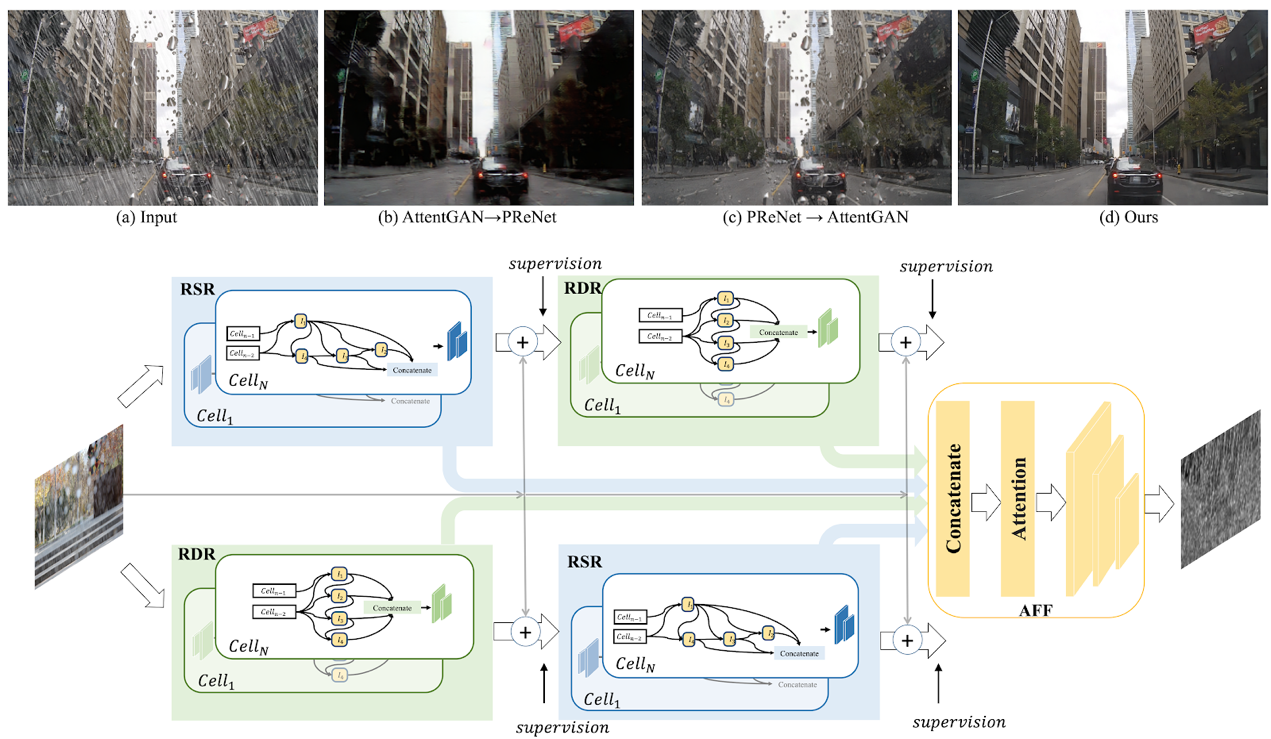
现有的去雨算法一般针对的是单一的去除雨线或者是去除雨滴问题,但是在现实场景中两种不同类型的雨往往同时存在。尤其是在下雨的自动驾驶场景中,空气中线条状的雨线和挡风玻璃上的椭圆形水滴都会严重影响车载摄像头捕捉的画面的清晰度,从而大幅降低了自动驾驶视觉算法的准确性。针对这一问题,本文首先设计一种互补型级连网络结构—CCN,能够在一个整体网络中以互补的方式去除两种形状和结构差异较大的雨。其次,目前公开数据集缺少同时含有雨线和雨滴的数据,对此本文提出了一个新的数据集RainDS,其中包括了雨线和雨滴数据以及它们相应的Ground Truth,并且该数据集同时包含了合成数据以及现实场景中拍摄的真实数据以用来弥合真实数据与合成数据之间的领域差异。实验表明,本文的方法在现有的雨线或者雨滴数据集以及提出的RainDS上都能实现很好的去雨效果。在实际应用中,使用一个整体的网络同时去除视野中的雨滴和雨线,可进一步帮助提升在下雨天气中自动驾驶视觉算法的准确性。
9.弱监督声音-视频解析中的异类线索探索
Exploring Heterogeneous Clues for Weakly-Supervised Audio-Visual Video Parsing
现有的音视频研究常常假设声音和视频信号中的事件是天然同步的,然而在日常视频中,同一时间可能音视频会存在不同的事件内容。比如一个视频画面播放的是足球赛,而声音听到的是解说员的话音。本文旨在精细化的研究分析视频中的事件,从视频和音频中分析出事件类别和其时间定位。本文针对通用视频,设计一套框架来从弱标签中学习这种精细化解析能力。该弱标签只是视频的标签(比如篮球赛、解说),并没有针对音视频轨道有区分标注,也没用时间位置标注。本文使用MIL(Multiple-instance Learning)来训练模型。然而,因为缺少时间标签,这种总体训练会损害网络的预测能力,可能在不同的时间上都会预测同样的事件。因此本文提出引入跨模态对比学习,来引导注意力网络关注到当前时刻的底层信息,避免被全局上下文信息主导。此外,本文希望能精准地分析出到底是视频还是音频中包含这个弱标签信息。因此,本文设计了一套通过交换音视频轨道来获取与模态相关的标签的算法,来去除掉模态无关的监督信号。具体来说,本文将一个视频与一个无关视频(标签不重合的视频)进行音视频轨道互换。本文对互换后的新视频进行标签预测。如果他对某事件类别的预测还是非常高的置信度,那么本文认为这个仅存的模态轨道里确实可能包含这个事件。否则,本文认为这个事件只在另一个模态中出现。通过这样的操作,本文可以为每个模态获取不同的标签。本文用这些改过的标签重新训练网络,避免了网络被模糊的全局标签误导,从而获得了更高的视频解析性能。该方法可以用来帮助精准定位爱奇艺等网络视频中的各类动作、事件。
10.基于双尺度一致性的六自由度物体姿态估计学习
DSC-PoseNet: Learning 6DoF Object Pose Estimation via Dual-scale Consistency
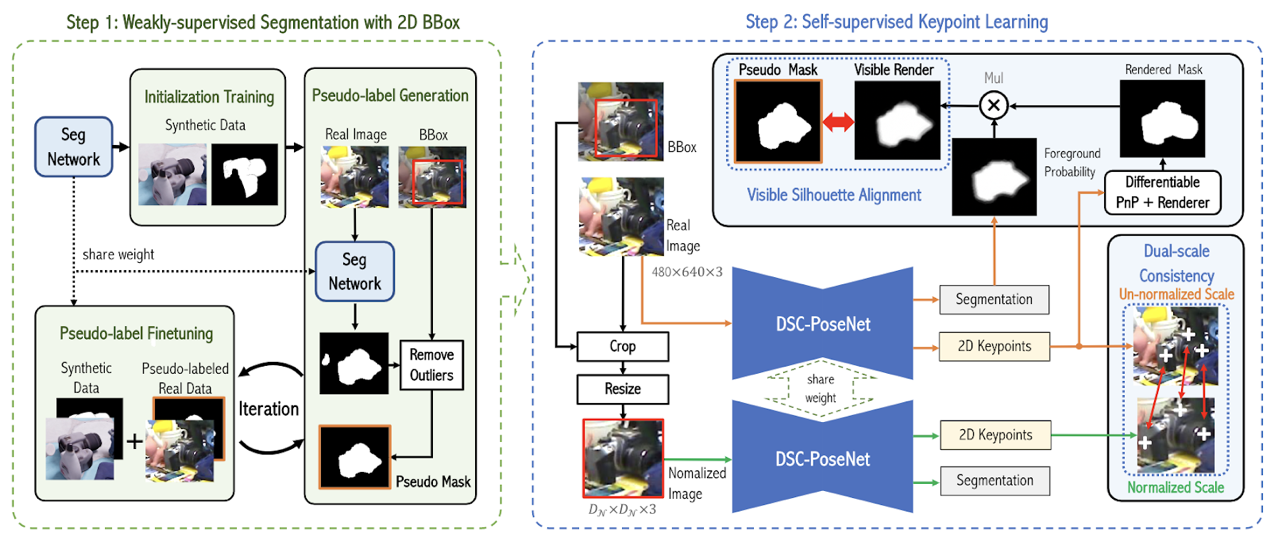
相比较于标注目标物体的二维外接框,人工标注三维姿态非常困难,特别是当物体的深度信息缺失的时候。为了减轻人工标注的压力,本文提出了一个两阶段的物体姿态估计框架,从物体的二维外接框中学习三维空间中的六自由度物体姿态。在第一阶段中,网络通过弱监督学习的方式从二维外接框中提取像素级别的分割掩模。在第二阶段中,本文设计了两种自监督一致性来训练网络预测物体姿态。这两种一致性分别为:1、双尺度预测一致性;2、分割-渲染的掩模一致性。为验证方法的有效性和泛化能力,本文在多个常用的基准数据集上进行了大量的实验。在只使用合成数据以及外接框标注的条件下,本文大幅超越了许多目前的最佳方法,甚至性能上达到了许多全监督方法的水平。
11.基于深度动态信息传播的单目3D检测
Depth-conditioned Dynamic Message Propagation for Monocular 3D Object Detection
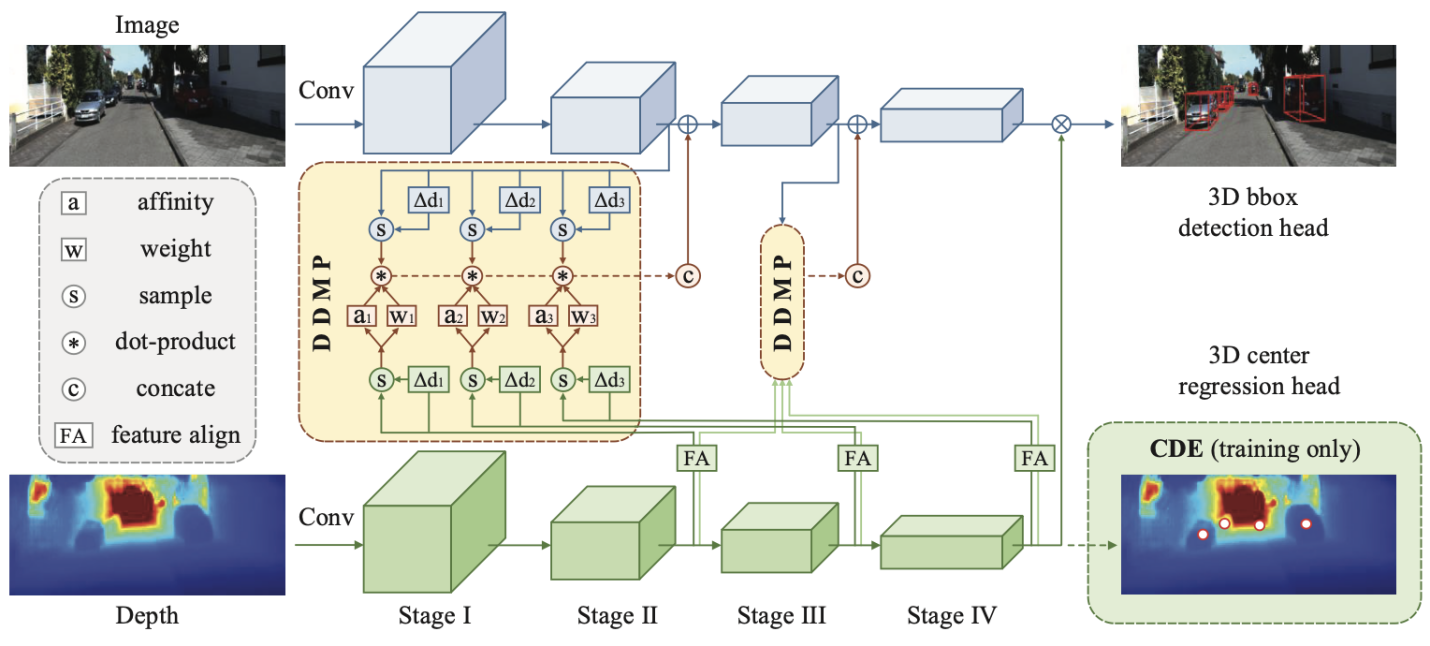
本文首次提出一种基于图信息传播模式的深度感知单目3D检测模型(DDMP-3D),以有效的学习单目图片3D目标的特征。具体来说,将每个特征像素视为图中的一个节点,本文首先从特征图中动态采样一个节点的邻域。通过自适应地选择图中最相关节点的子集,该操作允许网络有效地获取目标上下文信息。对于采样的节点,本文模拟图信息传播模式,使用深度特征为节点预测滤波器权重和亲和度矩阵,以通过采样的节点传播信息。此外,在传播过程中探索了多尺度深度特征,学习了混合滤波器权重和亲和度矩阵以适应各种尺度的物体。另外,为了解决先验深度图不准确的问题,本文增强了中心感知深度编码(CDE)作为在深度分支处附加的辅助任务。它通过3D目标中心回归任务,指导深度分支的中间特征具有中心感知能力,并进一步改善对象的定位。
这种基于单目的3D检测模型对于设备的要求较低(仅需要单个摄像头),容易在自动驾驶系统中实现应用。3D单目检测作为自动驾驶系统中的第一步,为后续的物体识别、系统决策等一系列任务做基础。
12.半监督迁移学习自适应一致性正则化
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
论文链接:https://arxiv.org/abs/2103.02193
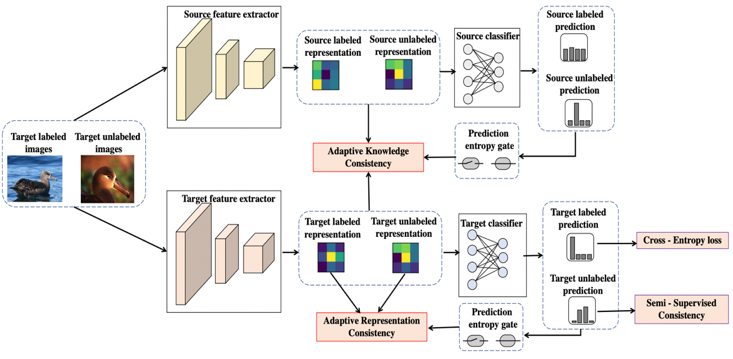
在标注样本稀缺的情况下,半监督学习作为一种有效利用无标签样本,进而提供模型效果的技术,受到广泛关注。预训练加迁移学习的方式是另一种高效训练优质模型的重要技术。本文研究了一个非常实用的场景,即在具备预训练模型的情况下进行半监督学习。本文提出了自适应一致性正则化技术来充分利用预训练模型和无标签样本的价值。具体的,该方法包含知识一致性(Adaptive Knowledge Consistency, AKC)和表征一致性(Adaptive Representation Consistency, ARC)两个组件。AKC利用全部样本保持预训练模型和目标模型的知识一致性,来保障目标模型的泛化能力;而ARC要求在有标签和无标签的样本之间保持表征的一致性,来降低目标模型的经验损失。自适应技术在这两项中用于选择有代表性的样本,以确保约束的可靠性。相比最新的半监督学习算法,本文的方法在通用数据集CIFAR-10/100,以及动物、场景、医疗三个特定领域的数据集上都获得明显的优势,并且能和MixMatch/FixMatch等最新方法叠加使用获得进一步提升,几乎没有额外的计算消耗。



